试图总结目标跟踪近四年的算法思想
emmmmmm,首先给上一张我见过好多次的图,虽然没找到他的出处,但是有一定的参考价值,我就按这个总结吧。
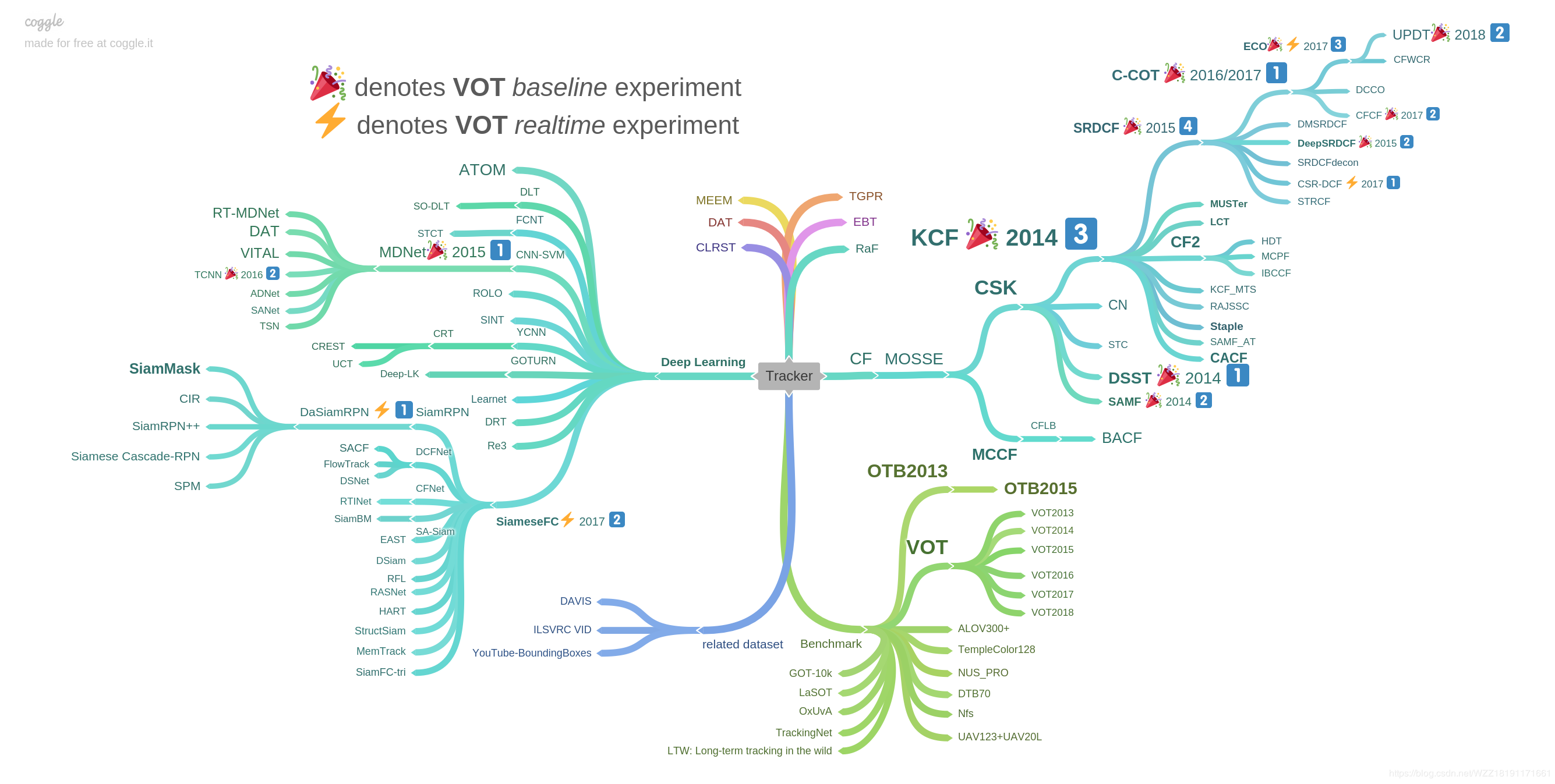
首先总结左边的基于深度学习的算法吧。
1 ATOM:
相关解析链接: https://blog.csdn.net/discoverer100/article/details/90374045 https://blog.csdn.net/sinat_27318881/article/details/84668861 直接引用其中一篇的总结: 在这篇论文中,作者将目标估计方法与判别思想进行了融合以期望得到一个更加健壮的跟踪器。对于目标估计方法,作者引入了IoU最大化的理念,使矩形框与目标真实位置更加贴近;对于目标分类方法,作者提出了自己的最优化策略,使模型收敛更快。
收获:将目标定位的估计和目标是否存在的分类做成两部分,有助于提高鲁棒性。
2 SO-DLT
这个的相关内容很少啊,就只找到一篇解析 https://blog.csdn.net/whfshuaisi/article/details/69053442 DLT (1) 先使用栈式降噪自编码器(stacked denoising autoencoder,SDAE)在Tiny Images dataset这样的大规模自然图像数据集上进行无监督的离线预训练来获得通用的物体表征能力。 (2) 取离线SDAE的encoding部分叠加sigmoid分类层组成了分类网络。 (3) 在目标跟踪非常重要的模型更新策略上,该论文采取限定阈值的方式,即当所有粒子中最高的confidence低于阈值时,认为目标已经发生了比较大的表观变化,当前的分类网络已经无法适应,需要进行更新。 SO-DLT (1) 处理第t帧时,首先以第t-1帧的的预测位置为中心,从小到大以不同尺度crop区域放入CNN当中,当CNN输出的probability map的总和高于一定阈值时,停止crop, 以当前尺度作为最佳的搜索区域大小。 (2) 选定第t帧的最佳搜索区域后,在该区域输出的probability map上采取一系列策略确定最终的bounding-box中心位置和大小。 (3) 在模型更新方面,为了解决使用不准确结果fine-tune导致的drift问题,使用了long-term 和short-term两个CNN,即CNNs和CNNl。CNNs更新频繁,使其对目标的表观变化及时响应。CNNl更新较少,使其对错误结果更加鲁棒。二者结合,取最confident的结果作为输出。从而在adaptation和drift之间达到一个均衡。
收获:在更新模型时使用长期更新策略和短期更新策略相结合。
3 STCT
解析: https://blog.csdn.net/autocyz/article/details/52565422 https://blog.csdn.net/autocyz/article/details/52565422
主要提到的是使用级联的分类器,致力于处理缺少样本,无法训练cnn的问题。 感觉对应之后样本的不断增多,这个方法的参考意义并不是太大。
收获:咕咕咕
4 MD-Net
解析链接: https://blog.csdn.net/sgfmby1994/article/details/79863613 https://blog.csdn.net/qq_40289855/article/details/82182232 https://zhuanlan.zhihu.com/p/45226738 https://www.cnblogs.com/wangxiaocvpr/p/5598608.html
出发点: 1、对于跟踪问题来说,CNN应该是由视频跟踪的数据训练得到的更为合理。所有的跟踪目标,虽然类别各不相同,但其实他们应该都存在某种共性,这是需要网络去学的。
2、用跟踪数据来训练很难,因为同一个object,在某个序列中是目标,在另外一个序列中可能就是背景,而且每个序列的目标存在相当大的差异,而且会经历各种挑战,比如遮挡、形变等等。
3、现有的很多训练好的网络主要针对的任务比如目标检测、分类、分割等的网络很大,因为他们要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景。而且目标一般都相对比较小,那么其实不需要这么大的网络,会增加计算负担。
针对这三点,作者提出了Multi-Domain Network,多域学习的网络结构,来学习这些目标的共性。
效果好的原因: 1.用了CNN特征,并且是专门为了tracking设计的网络,用tracking的数据集做了训练 2.有做在线的微调fine-tune,这一点虽然使得速度慢,但是对结果很重要 3.Candidates的采样同时也考虑到了尺度,使得对尺度变化的视频也相对鲁棒 4.Hard negative mining和bounding box regression这两个策略的使用,使得结果更加精确
收获:在训练网络的时候使用共享网络来训练特征提取部分,最后使用分类器进行分类,这样可以有效克服目标和背景在不同时候角色的相互转换。因为有的时候背景也会成为目标。
5 RT-MDnet
解析链接: https://blog.csdn.net/weixin_39467358/article/details/84990609 https://blog.csdn.net/qinhuai1994/article/details/82663107 提出基于MDNet的快速且准确跟踪算法
(1)通过感受野的高分辨特征图来区分目标和背景,通过改进RoIAlign加速特征提取,
(2)在嵌入空间中,通过mutli-task损失有效地区分目标,对具有相似语义的目标加入了具有辨别力的参数。
结果:与MDNet相比速度提高了25倍,精度几乎相同。
主要努力是提升速度,使用ROIAlign来克服量化损失。
收获:咕咕咕
6 VITAL
解析链接: https://blog.csdn.net/weixin_38493025/article/details/80674696
当前已有的基于神经网络的目标追踪算法大都是基于这样一个两阶段框架:
先是在目标可能出现的位置附近找出一系列样本; 然后对这些样本进行分类,判断是属于目标还是背景。 由此会导致追踪算法在以下两个层面受到限制:
每一帧上的正样本在空间上高度重叠,难以捕获到大规模形变; 类不均衡:正样本数远远小于负样本。 为了解决上述两个问题,作者提出了基于对抗学习的VITAL算法:
为了增强正样本数据,使用一个生成对抗式网络(GAN)随机产生遮罩mask,这些mask作用在输入特征上来捕获目标物体的一系列变化。在对抗学习的作用下,作者的网络能够识别出在整个时序中哪一种mask保留了目标物体的鲁棒性特征。 为了解决类不均衡问题,作者提出了一个高阶的代价敏感损失函数,用于降低简单负样本的影响力,促进网络的训练。
所以说是为了克服正样本太少,引入对抗神经网络。。。
收获:咕咕咕
7 TCNN
解析链接: https://blog.csdn.net/sinat_31184961/article/details/84023617
当前目标跟踪可分为生成式方法和判别式方法,生成式方法就是使用目标在当前帧上寻找匹配的区域,判别式方法是一个分类方法,就是区分前景和背景。以往的文章假设目标在两帧之间的变化不大,但是这种假设明显是有漏洞的,难处理遮挡、光线变化、突然的运动和变形等。 所以这篇文章使用多个CNN来表示目标的多种外观模型,然后对于每个候选框x,将其利用每个CNN算出来的值加权平均得到x的score而score最高的就是当前帧的target。
Contribution 1、我们提出了一种视觉跟踪算法,用于在树结构中基于CNN管理目标外观模型,其中模型沿树中的路径在线更新。 该策略使我们能够通过平滑更新来学习更多持久模型。 2、我们的跟踪算法采用多种模型来捕获不同的目标外观,并且即使遇到诸如外观变化,遮挡和临时跟踪故障等挑战,也能执行更强大的跟踪。 3、所提出的算法在标准跟踪基准中具有出色的准确性,并且通过大幅度优于最先进的方法。
使用多个特征模型,构成树形的模型,保留10帧的模型并不断改进。
收获:多提取特征,使用更多的特征来对抗遮挡,变化。
8 ADNet
解析链接: https://blog.csdn.net/ms961516792/article/details/81606634 https://blog.csdn.net/susansmile1014/article/details/77968635
通过预测动作来指导跟踪,是个不错的想法。 但是这个方法的初衷是为了避免预测边界框,从而减小计算量,这个在现在已经不是主要考虑的方向了 不过使用动作估计的方式减少检测范围从而提高速度还是可以借鉴的。
收获:提取多帧信息,预测目标运动方向位置。
9 siammask
解析链接: https://blog.csdn.net/WZZ18191171661/article/details/89035067
作者讲解视频:https://www.bilibili.com/video/av61878688
借鉴相关滤波的思想,训练相关函数,使用Row(候选窗口的相应图)来分别预测score,box,mask
速度块准确度高,但是应对目标遮挡时效果不好。因为没有短期学习和长期学习,或运动估计,仅仅时纯粹的深度学习,论文后边的优化好像有优化方案,但是还没有仔细研究,不够其中的训练相关函数,和使用Row来预测结果的方法十分值得借鉴。
想法:
作者提到了对目标意义的认知,其实是作者加上mask后,有了旋转边界框,使得iou更高,即边界框内目标更多了,然而背景更少了,这样仿佛网络真正认识了这个目标,但当测试那个蚂蚁的视频的时候就体现出,虽然网络认知了这个类型的物品,但是同类型物品之间的区分能力很弱,小女孩视频种体现出抗遮挡能力较弱,那么这里就应该借鉴一下一些运动估计的思想,在线更新模型的思想,和短期跟踪和长期跟踪的思想。相信这样可以使跟踪即在目标跟踪的精度上有较好效果,也在跟踪的抗遮挡性能,鲁棒性上更好。
收获:使用深度学习的方法构造相关函数
10 siamrpn++
解析链接: https://zhuanlan.zhihu.com/p/56254712
siamrpn基于SiamFC, 引入了Faster RCNN中的RPN模块,让tracker可以回归位置、形状,可以省掉多尺度测试,提高算法性能的同时算法的跟踪速度;
siamrpn++主要解决的问题是将深层基准网络ResNet、Inception等网络应用到基于孪生网络的跟踪网络中。
收获:使用多层的孪生网络,提取深度特征。
11 MOSSE
解析链接:https://blog.csdn.net/a133521741/article/details/81228339
最小输出平方误差(MOSSE)滤波器
MOSSE能够在初始化单个帧的时候产生稳健的滤波器。作者提到,基于MOSSE过滤器的跟踪器对照明、缩放、姿态和非刚性变形的变化非常有效,同时运行速度为669帧/秒。根据峰值-托旁比的比率(PSR)检测到遮挡,这使得跟踪器能够暂停并当对象重新出现时的位置重新开始追踪。
里边的理论是傅里叶变换的一些东西,解释链接: https://blog.csdn.net/autocyz/article/details/48136473
这个傅里叶变化是快速傅里叶变化还有复数域求导,emmmmmmm,我的数学有点不够用了。
用到的定理是:卷积定理:在时域的卷积即傅里叶域中元素的点乘。
不过大致还是知道,为了寻找一个可以得到最大相应图,我们需要寻找一个过滤器模板,为了抵抗变化,我们用了好几帧,然后对这个过滤模板求导,使倒数为0,就是我们需要的模板了。
收获:使用相关滤波和傅里叶变换和多帧的策略,得到一个鲁棒性较好的动态模型
12 KCF
解析链接: https://www.cnblogs.com/jins-note/p/10215511.html https://blog.csdn.net/a133521741/article/details/81228339 KCF的主要贡献 1 使用目标周围区域的循环矩阵采集正负样本,利用脊回归训练目标检测器,并成功的利用循环矩阵在傅里叶空间可对角化的性质将矩阵的运算转化为向量的Hadamad积,即元素的点乘,大大降低了运算量,提高了运算速度,使算法满足实时性要求。 2 将线性空间的脊回归通过核函数映射到非线性空间,在非线性空间通过求解一个对偶问题和某些常见的约束,同样的可以使用循环矩阵傅里叶空间对角化简化计算。 3 给出了一种将多通道数据融入该算法的途径。
收获:咕咕咕,看不懂呀。。。
13 SRDCF
解析链接: https://blog.csdn.net/qq_17783559/article/details/88088345
emmmm,实在KCF的基础上解决边界效应,因为KCF也没看懂,这里还是引用把
改进: 1、加入了空间正则来解决边界效应 2、使用Gauss-Seidel函数来求解滤波器
收获:咕咕咕
14 C-COT
解析链接: http://www.p-chao.com/2017-04-20/%E5%9B%BE%E5%83%8F%E8%B7%9F%E8%B8%AA%EF%BC%88%E5%8D%81%EF%BC%89c-cot%E7%AE%97%E6%B3%95%EF%BC%9A%E8%BF%9E%E7%BB%AD%E7%A9%BA%E9%97%B4%E5%9F%9F%E7%9A%84%E5%8D%B7%E7%A7%AF%E6%93%8D%E4%BD%9C/ https://blog.csdn.net/lixiaotong95/article/details/80448105
在最近的研究发现,最后一层的特征包含有较多的语义信息,能够很好的适用于做分类(classification),而底层的特征包含较多的视觉信息,能够很好的适用于做跟踪。高层特征的分辨率比较低,底层特征的分辨率比较高。
整体来说是根据作者发现的一个浅层网络保留的原始图像较多,而深层易于分类的发现,设计了对应的滤波模板,给出了滤波模板的公式。收到了较好的效果,emmmmmm,为啥总觉得滤波比深度学习复杂太多了。
收获:咕咕咕
15 ECO
解析链接: https://blog.csdn.net/zixiximm/article/details/54378397 https://blog.csdn.net/qq_40289855/article/details/82180379
总结一下ECO效果好的原因: 1 特征全面(CNN, HOG, CN),这个对结果的贡献很高; 2 相关滤波器经过筛选更具代表性(2.1做的),防止过拟合; 3 训练样本具有多样性(2.2做的),减少冗余; 4 非每帧更新模型,防止模型漂移;
收获:咕咕咕
16 UPDT
解析链接: https://gkwang.net/updt/
从本篇论文可以的出结论,浅层特征和深层特征需要分开训练,来取得更好的跟踪效果,此外,使用合适的融合策略也是非常重要的。
只是C—COT的论证+特征融合?