程序员的自我修养—链接、装载与库 第一章
程序员的自我修养—链接、装载与库 第一章
操作系统应用程序编程接口(Application Programming interface)
linux 是 Glic 库提供 POSIX 的 API
windows是 Windows API
运行库使用操作系统提供的 系统调用接口(System call interface)
系统调用接口在实现中往往以软件中断(software interruput)的方式提供。
比如linux使用0x80号中断作为系统调用接口,windows使用0x2E号中断作为系统调用接口(从windows xp Sp2开始windows开始采用一种新的系统调用方式)。
操作系统内核层对于硬件层来说是硬件接口的使用者,而硬件是接口的定义者,硬件的接口决定了操作系统内核,即驱动程序如何操作硬件。这种接口叫做硬件规格。
操作系统的功能是提供抽象的接口和管理硬件资源。
分析系统 多任务系统 抢占式系统
内存如果直接使用物理内存空间会导致:
程序之间可能会相互影响,内存分配需要物理上连续而导致使用效率底下,程序的运行地址不稳定。
所以引入了虚拟地址。
使用虚拟地址就有效的做的了进程间的隔离。
虚拟地址有时候会比物理地址要大。比如只有521MB的物理内存,但是x86的虚拟地址空间大小有4GB
为了进行程序分离首先引入了分段的概念,将虚拟地址的一段映射到物理地址的一段,这个地址转换由cpu完成。
但是仅仅使用分段不能解决空间利用率底下的问题,碎片化的内存间隙会导致内存利用率低。
根据程序的局部性原理,当一个程序在运行时,某一段时间内,它往往只是频繁的使用到了一小部分数据,那么就想到将程序所需要的内存进一步分割,就出现了分页的操作。
分页的基本方法就是把地址空间认为的等分成固定大小的页。
每一页的大小由硬件决定。或者硬件支持多种大小的页。
由操作系统选择分页的大小。每页可以是4KB,也可以是4MB,常用的是4KB。
32 位操作系统的 虚拟地址空间为4GB,可以分出 4GB/4KB=2^20个页
这样常用的页在内存中,不常用的页在磁盘中,这样就可以在有限的物理空间中装下更多现在需要用的页了,运行的程序就更多了。
虚拟空间中的页叫做虚拟页(virtual page),物理内存中的页叫做物理页(Physical page),磁盘中的页叫做磁盘页(Disk page)。
当进程需要用一个在虚拟页中的数据却不在物理页中的适合就会触发页错误(Page fault)然后操作系统将这个页从磁盘页调入物理页。
保护也是页映射的目的之一,每个页可以设置权限。
虚拟存储的实现是需要依赖硬件支持的。一般是用一个MMU(Memory management unit)的部件进行页映射。
在页映射模式下cpu处理的是virtual address,MMU转换后成为physical address。一般mmu是集成在了cpu中。
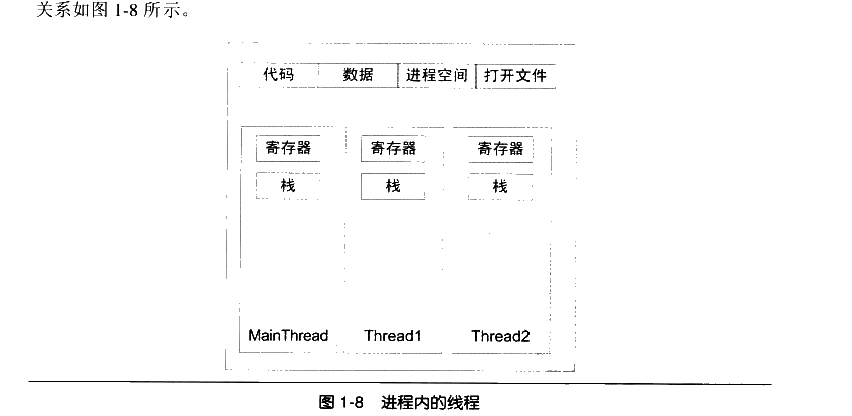
什么是线程:线程有时候被称作轻量级进程,是程序执行流的最小单位。一个标准的线程由线程id,当前指令指针PC,寄存器集合和堆栈组成。
通常意义上一个进程由多个线程组成,各个线程之间共享程序的内存空间(代码段,数据段,堆等)及一些进程级的资源(打开文件及信号)
使用多线程的原因有一下几点:
1 某个操作可能会陷入长时间的等待,等待的线程会进入睡眠状态,无法继续执行。多线程可以有效利用等待时间。典型的情况是等待网络响应。
2 某个操作会消耗大量时间,如果只有一个线程,用户的交互会卡死,可以单独一个线程不断的与用户交互,另一个干大量消耗时间的任务。
3 程序本身要求并发操作,例如一个多线程下载软件。
4 多核cpu本具备多线程能力,使用多线程可以更好的发挥硬件性能。
5 想对于多进程,多线程在数据共享方面效率高得多。
线程的访问权限十分自由,它可以访问进程中所有数据,包括其他线程的堆栈。
实际应用中线程也有其逻辑意义上的私有存储空间。
1 栈,(其他线程通过一些方法也可以访问,但是一般认为是私有的)
2 线程的局部存储(Thread local Storage, TLS)线程局部存储是某些操作系统为线程单独提供的私有空间,但通常容量有限。
3 寄存器,寄存器是执行流的基本数据,因此线程私有

不论在单处理器上还是多处理器上,线程总是“并发”执行的,当线程数量小于等于处理器数量的时候,线程是真正的并发(每个线程在不同的处理器上同时运行)
在单处理器上的多线程是模拟出来的并发,每个线程轮流执行,每个人执行一小段时间,线程在处理器上被不断切换的现象叫做线程调度(Thread Schedule)。
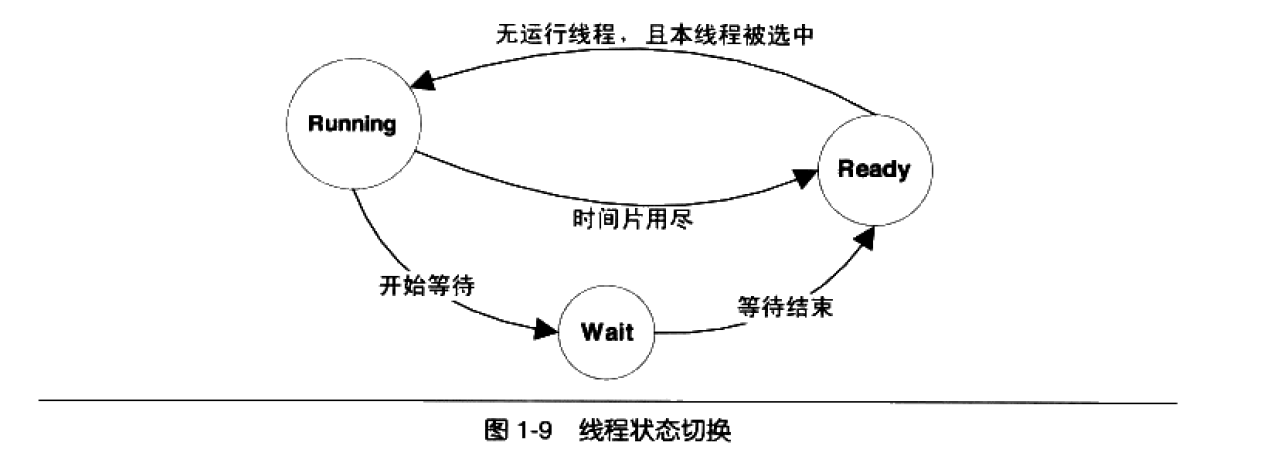
在线程调度中,线程通常拥有至少三种状态:
运行:此时线程正在运行
就绪:此线程可以立刻运行,但cpu被占用
等待:等待某一事件发生,无法执行
处于运行中线程的可执行时间成为时间片。
当时间片用尽时该线程就会进入就绪状态。
如果在时间片用尽前就开始等待某件事情,那进入等待状态。
每当一个线程离开运行态时,调度系统就会选择一个其他就绪线程继续执行。
当一个处于等待状态的线程所等待的事情发生后,该新城将进入就绪状态。
线程调度算法:
优先级调度,轮转法
轮转法指每个线程轮流执行一小段时间,优先级决定按照什么顺序轮流执行。
在具有优先级调度的系统中,线程都拥有自己各自的线程优先级。具有高优先级的线程会更早的执行,而低优先级的线程常常要等待到系统中没有高级优先级的可执行线程了,才能够执行。
在windows中设置线程优先级的函数是
BOOL WINAPI SetThreadPriority(HANDLE hThread, int nPriority);
频繁等待的线程只占用较少的时间,成为IO密集型线程(IO Bound Thread),而等待时间少的线程称为CPU密集型线程(CPU Bound Thread)。
在优先级调度下可能存在线程的饿死现象,即优先级较低的线程一直无法得到执行。为了避免饿死现象,调度系统常常会逐步提升那些等待了过长时间得不到执行的线程的优先级。
线程的优先级改变一般有三种方式:
1 用户指定优先级
2 根据进入等待状态的频繁程度提升或降低优先级
3 长时间得不到执行而被提升优先级
可抢占线程和不可抢占线程
单纯的轮转算法在线程的时间片用完后会被强制剥夺继续执行的权力,进入就绪状态。这种被强制剥夺的方式叫做抢占,即之后的线程抢占了当前线程的执行权力。早期的一些系统是非抢占式的。运行的线程必须自己发出一个放弃执行的命令,才能让其他线程得到执行。
linux的多线程
windows有明确的进程和线程,但linux内核中不存在真正意义上的线程。linux将所有的执行实体(线程和进程)都称为任务(Task)。每个任务在概念上都类似于一个单线程的进程,具有内存空间,执行实体,文件资源等。不过,linux下的不同任务之间可以选择共享内存空间,因而在实际意义上,共享了同一个内存空间的多个任务构成了一个进程,这些任务也就成了这个进程里的线程。
在linux上有一下几种方法创建任务:
| 系统调用 | 作用 |
|---|---|
| fork | 复制当前进程 |
| exec | 使用新的可执行英雄覆盖当前可执行映像 |
| clone | 创建子进程并从指定位置开始执行 |
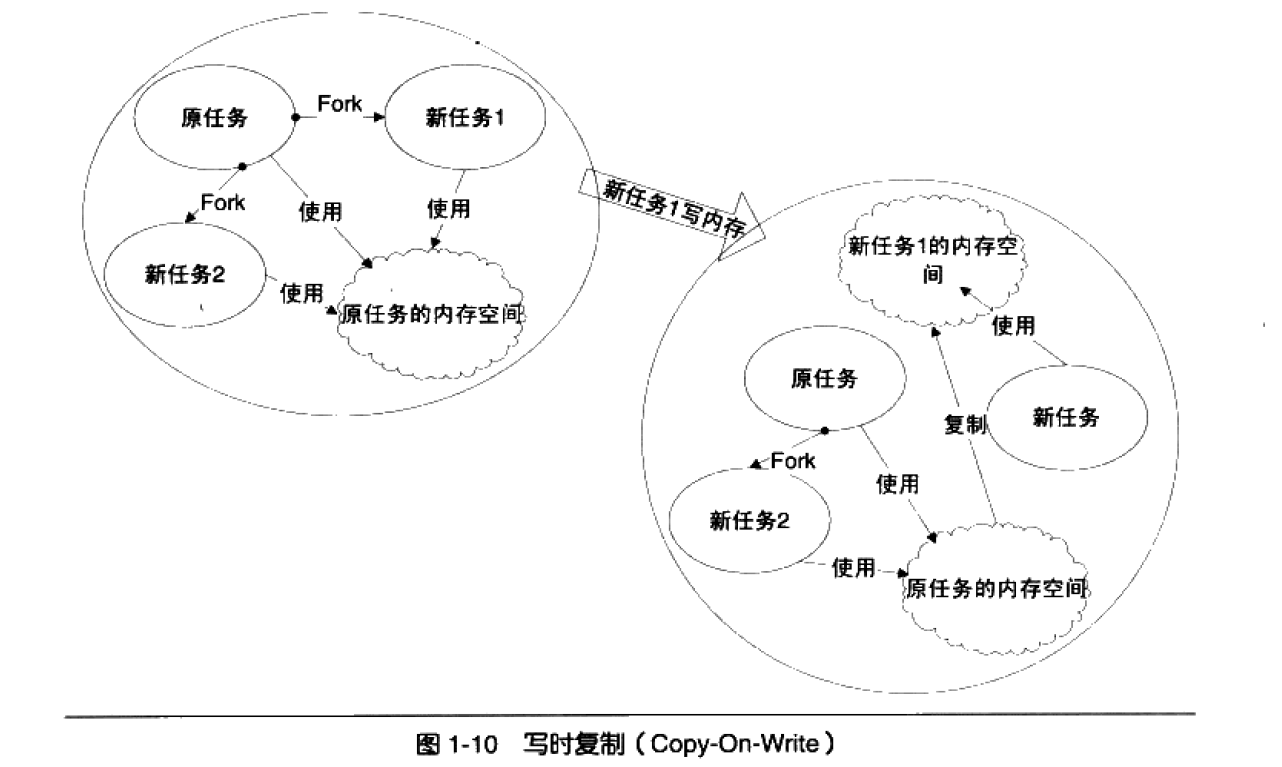
fork函数会产生一个和当前进程完全一样的新进程,并和当前进程一样从fork函数中返回。
pid_t= pid;
if(pid=fork())
{
...
}
本任务的fork返回是新任务的pid,新的任务返回的是0.
fork产生新的任务非常快,因为fork并不复制原任务的内存空间,而是和原任务一起共享一个写时复制(Copy on write, COW)的内存空间。所谓写时复制,指的是两个任务可以同时自由的读取内存,但是任意一个任务试图对内存进行修改时,内存就会复制一份提供给修改方单独使用,以免影响到其他任务使用。
fork只能产生本任务的镜像,所以要配合exec才能创建新的任务。
fork和exec通常用于产生新任务,如果要产生新的线程,可以使用clone
int clone(int (*fn)(void*), void* child_stack, int flags, void *arg);
1.6.2 线程安全
多线程并发时数据的一致性十分重要。
竞争和原子操作
多个线程同时读写一个共享数据时可能会产生问题。
| 线程1 | 线程2 |
|---|---|
| i=1;i++; | --i; |
在许多体系结构上,i++;的实现如下:
1 读取i到某个寄存器x 2 x++ 3 将x的内容写回i
单由于线程1加的同时,线程2在减,导致最终写回到i结果无法预测。
错误的原因在于它不是之间用的内存计算的,并且一个命令无法在一瞬间完成,可能会在其运行过程中有其他人也访问了这个变量,假如++命令就只是一条汇编命令,cpu只有一个核,那么cpu能在一瞬间完成++而不被其他命令影响,这样结果就不会错。
我们把单指令的操作称为原子的(Atomic)。
单条指令的执行时不会被打断的。为了避免出错,很多体系结构都提供了一些常用的原子指令,例如在i386就有一条inc指令可以直接增加一个内存单元值,可以避免出现上述例子的错误。
在windows中,有一套API专门进行一些原子操作,这种API称为interlocked API。
| windows API | 作用 |
|---|---|
| InterlockedExchange | 原子的交换两个值 |
| InterlockedDecrement | 原子的减少一个值 |
| InterlockedIncrement | 原子的增加一个值 |
| InterlockedXor | 原子的进行异或操作 |
使用这些函数时,windows将保证时原子操作的。
尽管原子操作指令十分方便,单他们仅仅适用于比较简单的特定场合。
在复杂场合下,我们需要更加通用的手段,锁。
同步与锁
为了避免多线程同时对一个数据进行读写,需要将各个线程对同一个数据的访问进行同步(Synchronization)。即是指在一个线程对数据读写未结束时,其他线程不得对同一个数据进行读写。如此,对数据的读写被原子化了。
同步最常见的方法时使用锁。锁是一种非强制机制,每一个线程在访问数据或资源之前首先试图获取锁,并在访问结束之后释放锁。在锁已经被占用的时候获取锁,线程会等待,直到锁重新可用。
二元信号量(Bianry Semaphore)是最简单的一种锁,它只有两种状态,占用和非占用。它适合只能被唯一一个线程独占访问的资源。当二元信号量处于非占用状态时,第一个试图获取该二元信号量的线程会获得该锁,并将二元信号量置为占用状态,此后其他的所有试图获得该二元信号量的线程都会等待,直到该锁被释放。
对于允许对各线程并发访问的资源,多元信号量 简称 信号量(Semaphore),它是一个很好的选择。一个初始值为N的信号量允许N个线程并发访问。线程访问资源的时候首先获取信号量。操作如下:
1 将信号量减1 2 如果信号量的值小于0,则进入等待状态,否则继续执行。访问完资源后,线程释放信号量 3 将信号量加1 4 如果信号量的值小于1,唤醒一个等待中的线程